Friendli Engine
About Friendli Engine
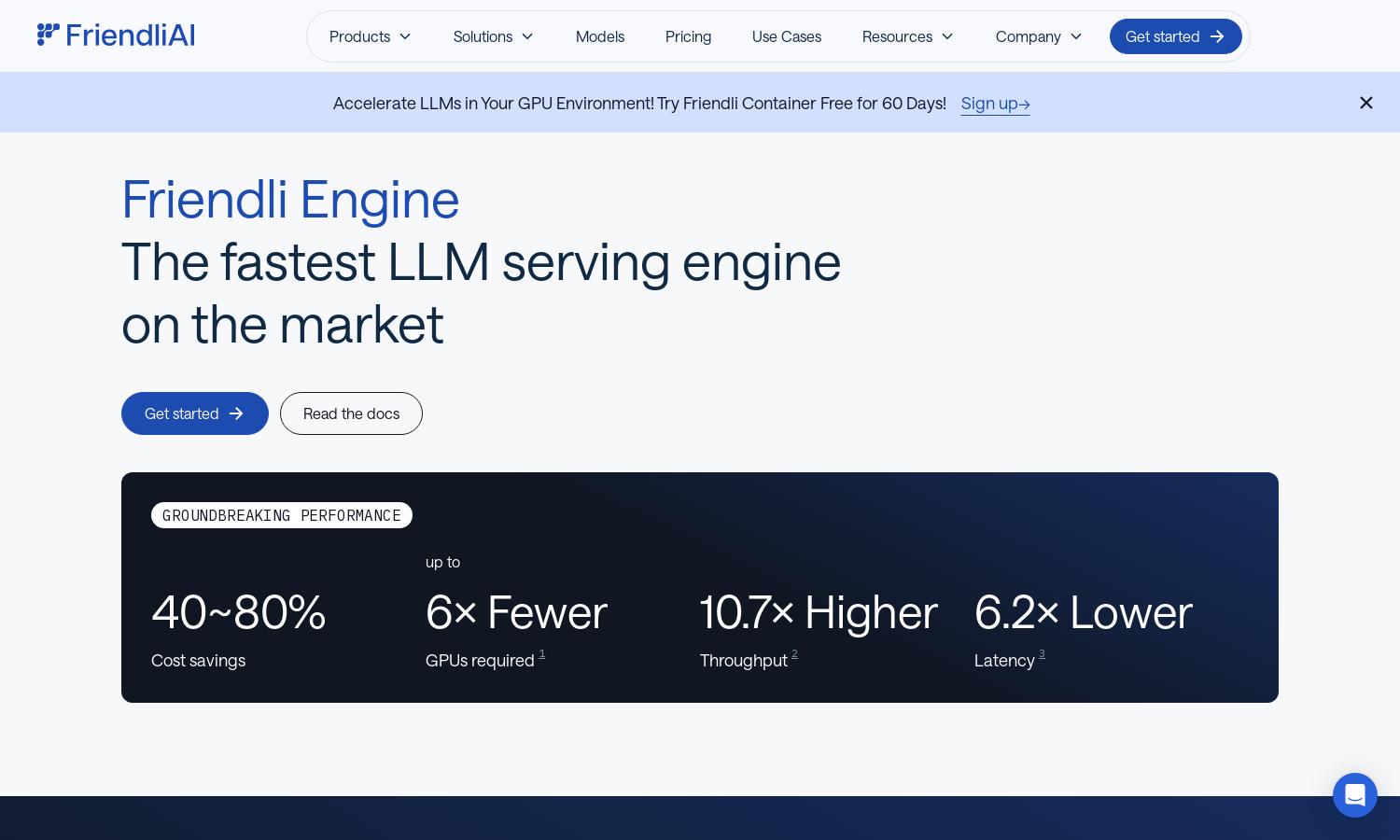
Friendli Engine is designed for organizations seeking rapid LLM inference. This platform excels with innovative features like Iteration Batching, enhancing throughput dramatically. Users can deploy various AI models efficiently, gaining significant cost savings and improved response times. Friendli Engine empowers teams to maximize AI potential seamlessly.
Pricing plans for Friendli Engine cater to different user needs, offering competitive rates. Each tier includes comprehensive support and advanced features tailored to enhance user experience. Upgrading unlocks additional performance capabilities, ensuring users get optimal value and efficiency from their LLM applications.
Friendli Engine boasts a user-friendly interface that streamlines interactions, making LLM inference effortless. Its design prioritizes quick navigation, allowing users to access features seamlessly. By integrating intuitive controls and clear layout, Friendli Engine ensures that users enjoy a smooth and efficient browsing experience.
How Friendli Engine works
Users begin by onboarding with Friendli Engine, setting up their generative AI models easily. They navigate the interface to select features such as Iteration Batching and Multi-LoRA support. The platform guides users through deployment, allowing them to run LLM inferences efficiently, all while ensuring optimal performance and cost savings.
Key Features for Friendli Engine
Iteration Batching Technology
Friendli Engine introduces Iteration Batching, enhancing LLM performance dramatically. This patented technology allows users to handle concurrent requests efficiently, improving throughput and maintaining low latency. As a result, Friendli Engine empowers users to achieve superior inference speed and operational cost savings.
Multi-LoRA Model Support
With Friendli Engine’s Multi-LoRA support, users can run multiple LoRA models on fewer GPUs, optimizing resource usage. This functionality simplifies LLM customization and enhances efficiency for AI developers, making advanced model management accessible and effective, driving innovation in generative AI applications.
Friendli TCache
Friendli TCache intelligently stores frequently used computations, enhancing efficiency in LLM inference. This feature reduces the computational burden on GPUs, delivering faster response times. For users of Friendli Engine, TCache represents a significant advantage in optimizing performance and saving resources during AI model deployments.








