Agenta
Agenta is an open-source LLMOps platform that unifies teams to build reliable AI applications with streamlined.
Visit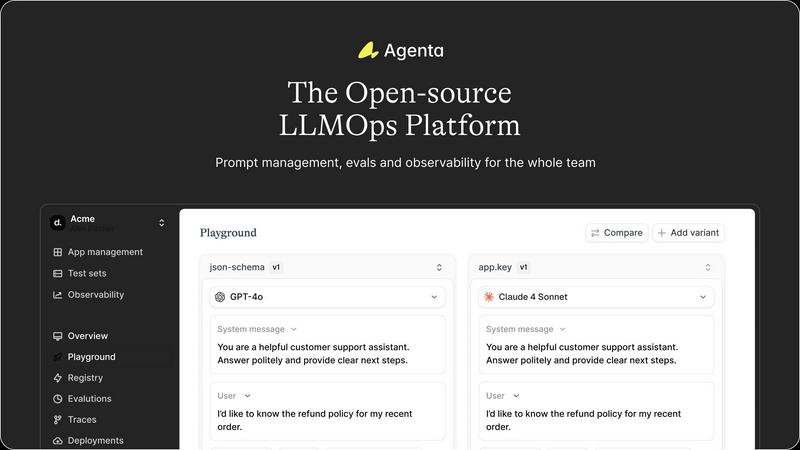
About Agenta
Agenta is the definitive open-source LLMOps platform meticulously crafted for sophisticated AI teams intent on developing and deploying reliable, production-grade LLM applications. In an era where the complexities of large language model (LLM) development often lead to chaos—characterized by scattered prompts, siloed teams, and unvalidated deployments—Agenta emerges as a beacon of order and efficiency. This platform not only centralizes the entire LLM development lifecycle but also fosters collaboration among developers, product managers, and domain experts. With Agenta, organizations can transform their fragmented workflows into structured, evidence-driven processes. By providing a single source of truth, it enables teams to experiment with prompts and models, conduct systematic evaluations, and debug issues with unparalleled precision. Agenta empowers organizations to replace guesswork with governance, ensuring the delivery of innovative and reliable AI products that meet market demands while upholding the highest quality standards.
Features of Agenta
Centralized Management
Agenta consolidates all elements of LLM development, including prompts, evaluations, and traces, into one cohesive platform. This centralization eliminates the chaos of disparate tools and provides a streamlined approach to managing the entire LLM lifecycle.
Unified Playground
With Agenta's unified playground, teams can compare different prompts and models side-by-side, allowing for comprehensive analysis and informed decision-making. This feature supports quick iterations and fosters an environment of continuous improvement.
Automated Evaluation
Agenta facilitates a systematic process for running experiments and tracking results through automated evaluations. By integrating various evaluators—including LLM-as-a-judge and custom code evaluators—teams can validate changes with confidence and precision.
Observability and Debugging
With robust observability features, Agenta enables teams to trace every request and identify exact failure points within their AI systems. This functionality enhances debugging capabilities, allowing teams to annotate traces collaboratively and turn any trace into a test with a single click.
Use Cases of Agenta
Collaborative Prompt Development
Agenta is ideal for teams seeking to enhance their collaborative efforts in prompt development. By providing a shared platform, teams can experiment, compare, and version prompts collectively, thereby improving the overall quality of their LLM applications.
Systematic Evaluation Processes
Organizations can leverage Agenta to implement systematic evaluation processes for their AI models. By tracking results and validating every change, teams can ensure that their models are continuously improving and meeting performance benchmarks.
Debugging and Trace Management
When issues arise, Agenta provides the tools necessary for effective debugging. Teams can trace requests, identify failure points, and gather user feedback, thus enabling a rapid response to problems and fostering a culture of continuous improvement.
Integration with Existing Workflows
Agenta seamlessly integrates with existing tools and frameworks, such as LangChain and OpenAI, making it an invaluable asset for organizations looking to enhance their LLMOps capabilities without disrupting their current workflows.
Frequently Asked Questions
What types of teams can benefit from Agenta?
Agenta is designed for a diverse range of teams, including developers, product managers, data scientists, and domain experts. Its collaborative features unify these roles, enhancing communication and workflow efficiency.
How does Agenta enhance collaboration among team members?
Agenta provides a centralized platform where team members can share prompts, conduct evaluations, and debug issues together. This collaborative environment fosters transparency and encourages collective problem-solving.
Is Agenta suitable for both small and large organizations?
Absolutely. Agenta's scalable architecture makes it suitable for organizations of all sizes, from startups to large enterprises, enabling them to adopt best practices in LLMOps regardless of their scale.
Can I integrate Agenta with my existing LLM frameworks?
Yes, Agenta is designed to integrate seamlessly with various LLM frameworks and tools, allowing teams to build upon their existing infrastructure without facing vendor lock-in or unnecessary complications.
Explore more in this category:
Similar to Agenta
JustHunt
JustHunt is the premier launchpad for startups, offering guaranteed visibility and community feedback to elevate your domain rating and success.