Crawlkit
Crawlkit seamlessly transforms any website into structured data with a single API call, empowering your development.
Visit
About Crawlkit
Crawlkit is the quintessential web data extraction platform meticulously crafted for developers and advanced data teams seeking a reliable and scalable solution to web data access. In a digital landscape rife with challenges such as sophisticated anti-bot measures, rotating proxies, headless browser rendering, and stringent rate limits, Crawlkit acts as a beacon of efficiency and simplicity. It alleviates the burdens of constructing and maintaining scraping infrastructure, allowing teams to focus on extracting valuable insights rather than getting bogged down in operational complexities. Through a single, unified API interface, developers can submit requests and receive clean, structured data effortlessly. Crawlkit's robust engine autonomously manages proxy rotation, JavaScript rendering, automatic retries, and anti-blocking techniques, ensuring that users receive comprehensive, actionable data. Supporting a diverse array of data types—from raw HTML to structured search results and visual snapshots—Crawlkit transforms the chaotic web into a structured resource, enabling teams to harness the power of data like never before.
Features of Crawlkit
Unified API Access
Crawlkit offers a single, consistent API interface that allows users to extract structured data from various sources, including websites, social platforms, and app stores, with just one request.
Advanced Proxy Management
The platform features built-in proxy rotation and management, ensuring that requests are seamlessly handled without the risk of being blocked, allowing for uninterrupted data extraction.
Comprehensive Data Types
Crawlkit supports a wide range of data types, from detailed company profiles on LinkedIn to reviews and ratings from app stores, making it a versatile tool for diverse analytical needs.
Automatic Data Validation
With Crawlkit, users receive always-complete results as the system waits for full page loads and validates responses, eliminating the hassle of dealing with partial or broken outputs.
Use Cases of Crawlkit
CRM Enrichment
Crawlkit can significantly enhance customer relationship management systems by automatically enriching profiles with LinkedIn data, capturing job titles, company details, and contact information for leads.
Competitive Intelligence
Businesses can leverage Crawlkit to monitor competitors' social media engagement and growth trends, such as follower counts and interaction rates on platforms like Instagram, to inform strategic decisions.
Market Research
Research teams can utilize Crawlkit to gather and analyze data from various online sources, enabling them to gain insights into market trends, consumer behavior, and competitive landscapes.
App Review Analysis
Crawlkit facilitates the extraction of app reviews and ratings from both the App Store and Google Play, allowing developers and marketers to analyze user feedback and improve their applications accordingly.
Frequently Asked Questions
What types of data can I extract with Crawlkit?
Crawlkit allows users to extract a variety of data types, including structured information from social media platforms, websites, and app stores, making it a comprehensive solution for diverse data needs.
How does Crawlkit handle anti-bot protections?
Crawlkit employs sophisticated techniques such as proxy rotation and anti-blocking measures to navigate through anti-bot protections, ensuring seamless and reliable data extraction.
Is there a limit to the number of API calls I can make?
Crawlkit operates on a credit-based system, allowing users to make API calls without monthly commitments or rate limits. Users can purchase credits based on their needs.
Can I integrate Crawlkit with my existing tools?
Absolutely. Crawlkit is designed as a simple HTTP API that can be utilized from any programming language or automation tool, ensuring maximum flexibility and compatibility with your existing workflows.
Explore more in this category:
Similar to Crawlkit
InContekst
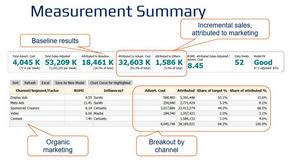
Decision support framework for high consideration businesses with mix of online and offline channels, content-rich sites, and long customer journeys.

Pages that Print
High-converting SaaS landing pages backed by verified revenue data. We expose the exact copywriting and design patterns that actually print money.
EnsembleData
EnsembleData provides real-time, scalable APIs for extracting social media data to power business analytics and research.

Shadcn Examples
Shadcn Examples offers elegant React and Tailwind UI kits with reusable components for creating stunning web applications effortlessly.
Subiq
Subiq brings clarity and control to your team's SaaS subscriptions, eliminating wasted spend on forgotten tools.